
Giovedì, i ricercatori Microsoft hanno annunciato un nuovo modello di intelligenza artificiale di sintesi vocale chiamato VALL-E che può simulare da vicino la voce di una persona quando viene fornito un campione audio di tre secondi. Una volta appresa una voce specifica, VALL-E può sintetizzare l’audio di quella persona che dice qualsiasi cosa e farlo in un modo che tenti di preservare il tono emotivo di chi parla.
I suoi creatori ipotizzano che VALL-E potrebbe essere utilizzato per applicazioni di sintesi vocale di alta qualità, editing vocale in cui una registrazione di una persona potrebbe essere modificata e modificata da una trascrizione di testo (facendogli dire qualcosa che originariamente non diceva), e la creazione di contenuti audio se combinati con altri modelli di intelligenza artificiale generativa come GPT-3 .
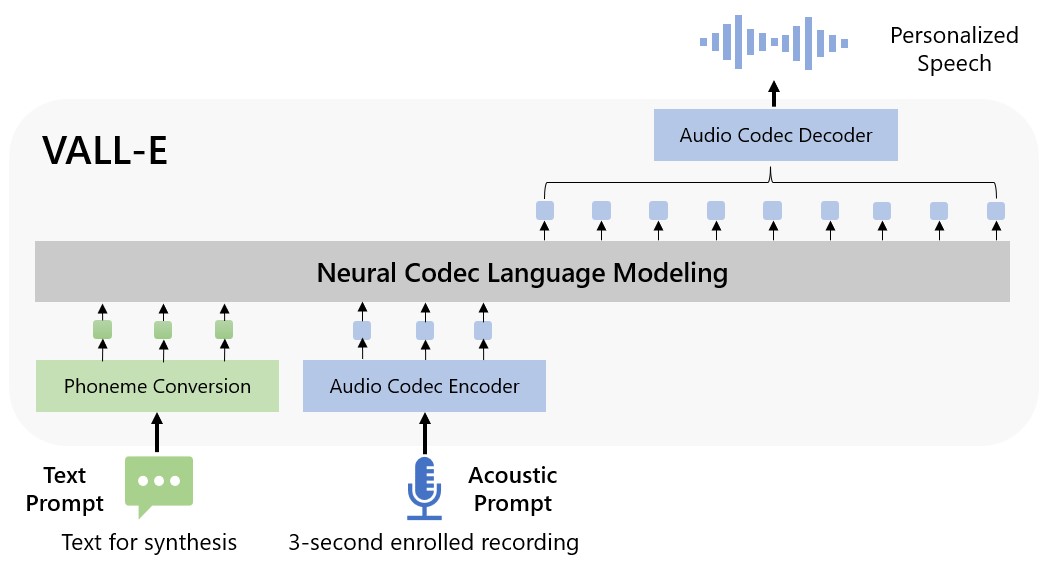
Microsoft chiama VALL-E un “modello di linguaggio codec neurale” e si basa su una tecnologia chiamata EnCodec, annunciata da Meta nell’ottobre 2022. A differenza di altri metodi di sintesi vocale che in genere sintetizzano il parlato manipolando le forme d’onda, VALL-E genera codici di codec audio discreti da messaggi di testo e acustici. Fondamentalmente analizza come suona una persona, suddivide tali informazioni in componenti discreti (chiamati “token”) grazie a EnCodec e utilizza i dati di addestramento per abbinare ciò che “sa” su come suonerebbe quella voce se pronunciasse altre frasi al di fuori delle tre -secondo campione. Oppure, come afferma Microsoft nel documento VALL-E :
Per sintetizzare il discorso personalizzato (ad esempio, TTS zero-shot), VALL-E genera i token acustici corrispondenti condizionati sui token acustici della registrazione registrata di 3 secondi e del prompt del fonema, che vincolano rispettivamente l’oratore e le informazioni sul contenuto. Infine, i token acustici generati vengono utilizzati per sintetizzare la forma d’onda finale con il decodificatore del codec neurale corrispondente.
Microsoft ha addestrato le capacità di sintesi vocale di VALL-E su una libreria audio, assemblata da Meta, chiamata LibriLight . Contiene 60.000 ore di discorsi in lingua inglese di oltre 7.000 parlanti, per lo più estratti da audiolibri di pubblico dominio LibriVox . Affinché VALL-E generi un buon risultato, la voce nel campione di tre secondi deve corrispondere strettamente a una voce nei dati di addestramento.
Sul sito Web di esempio VALL-E , Microsoft fornisce dozzine di esempi audio del modello AI in azione. Tra i campioni, “Speaker Prompt” è l’audio di tre secondi fornito a VALL-E che deve imitare. La “verità fondamentale” è una registrazione preesistente di quello stesso oratore che pronuncia una particolare frase a scopo di confronto (un po’ come il “controllo” nell’esperimento). La “linea di base” è un esempio di sintesi fornita da un metodo di sintesi vocale convenzionale e il campione “VALL-E” è l’output del modello VALL-E.
Durante l’utilizzo di VALL-E per generare questi risultati, i ricercatori hanno inserito solo il campione “Speaker Prompt” di tre secondi e una stringa di testo (quello che volevano che la voce dicesse) in VALL-E. Quindi confronta il campione “Ground Truth” con il campione “VALL-E”. In alcuni casi, i due campioni sono molto vicini. Alcuni risultati VALL-E sembrano generati dal computer, ma altri potrebbero potenzialmente essere scambiati per il discorso di un essere umano, che è l’obiettivo del modello.
Oltre a preservare il timbro vocale e il tono emotivo di un oratore, VALL-E può anche imitare “l’ambiente acustico” dell’audio campione. Ad esempio, se il campione proviene da una telefonata, l’uscita audio simulerà le proprietà acustiche e di frequenza di una telefonata nella sua uscita sintetizzata (è un modo elegante per dire che suonerà anche come una telefonata). E gli esempi di Microsoft (nella sezione “Sintesi della diversità”) dimostrano che VALL-E può generare variazioni nel tono della voce modificando il seme casuale utilizzato nel processo di generazione.
Forse a causa della capacità di VALL-E di alimentare potenzialmente malizia e inganno, Microsoft non ha fornito il codice VALL-E affinché altri possano sperimentarlo, quindi non abbiamo potuto testare le capacità di VALL-E. I ricercatori sembrano consapevoli del potenziale danno sociale che questa tecnologia potrebbe portare. Per la conclusione del documento, scrivono:
“Poiché VALL-E potrebbe sintetizzare il discorso che mantiene l’identità del parlante, potrebbe comportare potenziali rischi nell’uso improprio del modello, come lo spoofing dell’identificazione vocale o l’impersonificazione di un parlante specifico. Per mitigare tali rischi, è possibile costruire un modello di rilevamento per discriminare se una clip audio è stata sintetizzata da VALL-E. Metteremo in pratica anche i principi di intelligenza artificiale di Microsoft durante l’ulteriore sviluppo dei modelli”.