
Imparare Git è facile come usare lo strumento. Il motivo di questo blog tutorial su Git è di omettere questo dilemma dalla tua mente. Sono sicuro che con questo blog tutorial su Git, passerai in rassegna tutti i concetti.
Prima di iniziare con i comandi e le operazioni, cerchiamo di comprendere il motivo principale di Git.
Il motivo di Git è gestire un progetto o un insieme di file man mano che cambiano nel tempo. Git memorizza queste informazioni in una struttura di dati chiamata repository Git. Il repository è il cuore di Git.
Come faccio a vedere il mio repository GIT?
Per essere molto chiari, un repository Git è la directory in cui risiedono tutti i file di progetto e i relativi metadati.
Git registra lo stato corrente del progetto creando un grafico ad albero dall’indice. Di solito è sotto forma di un grafico aciclico diretto (DAG).
Prima di andare avanti, dai un’occhiata a questo video su Git tutorial per avere una visione migliore.
Ora che hai capito cosa vuole ottenere Git, andiamo avanti con le operazioni e i comandi.
Come imparo i comandi Git?
Una panoramica di base su come funziona Git:
- Crea un “repository” (progetto) con uno strumento di hosting git (come Bitbucket)
- Copia (o clona) il repository sul tuo computer locale
- Aggiungi un file al tuo repository locale e “commit” (salva) le modifiche
- “Spingi” le tue modifiche al tuo ramo principale
- Apporta una modifica al tuo file con uno strumento di hosting git ed esegui il commit
- “Trascina” le modifiche sulla tua macchina locale
- Creare un “ramo” (versione), apportare una modifica, confermare la modifica
- Apri una “richiesta pull”.
- “Unisci” il tuo ramo al ramo principale
Qual è la differenza tra Git Shell e Git Bash?
Git Bash e Git Shell sono due diversi programmi a riga di comando che consentono di interagire con il programma Git sottostante. Bash è una riga di comando basata su Linux mentre Shell è una riga di comando nativa di Windows.
Git Tutorial – Alcune operazioni e comandi
Alcune delle operazioni di base in Git sono:
- Inizializzare
- Aggiungere
- Commettere
- Tiro
- Spingere
Alcune operazioni Git avanzate sono:
- Ramificazione
- Fusione
- Ribasatura
Permettetemi prima di darvi una breve idea su come funzionano queste operazioni con i repository Git. Dai un’occhiata all’architettura di Git di seguito:
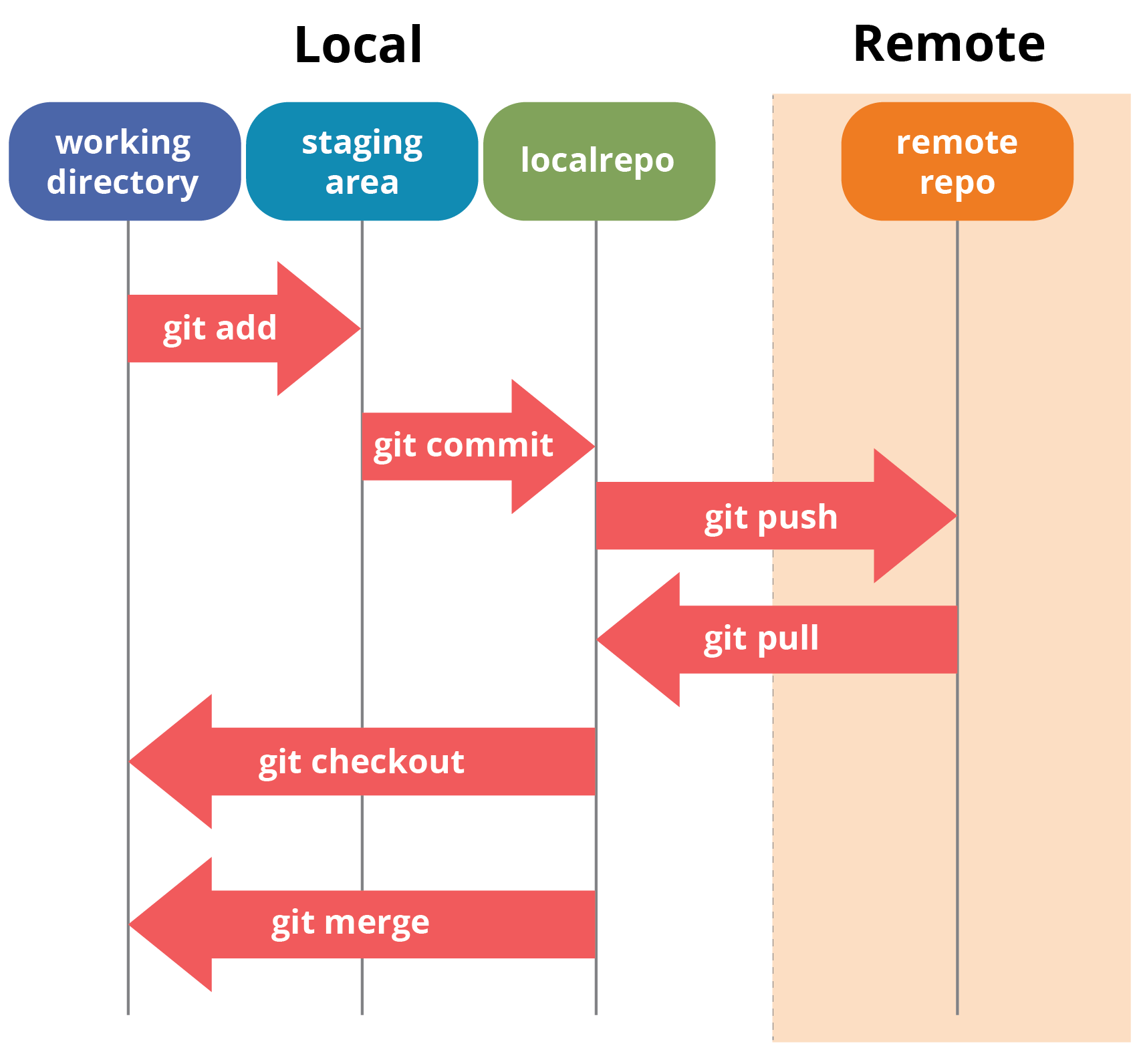
Se capisci bene e bene il diagramma sopra, ma in caso contrario, non devi preoccuparti, spiegherò queste operazioni in questo Tutorial Git una per una. Cominciamo con le operazioni di base.
Devi prima installare Git sul tuo sistema. Se hai bisogno di aiuto con l’installazione, clicca qui .
A cosa serve Git Bash?
Questo tutorial su Git Bash si concentra sui comandi e sulle operazioni che possono essere utilizzati su Git Bash.
Nota : i comandi non possono essere eseguiti su GitHub.
Dopo aver installato Git nel tuo sistema Windows, apri la cartella/directory in cui desideri archiviare tutti i file di progetto; fare clic con il tasto destro e selezionare ‘ Git Bash qui ‘.
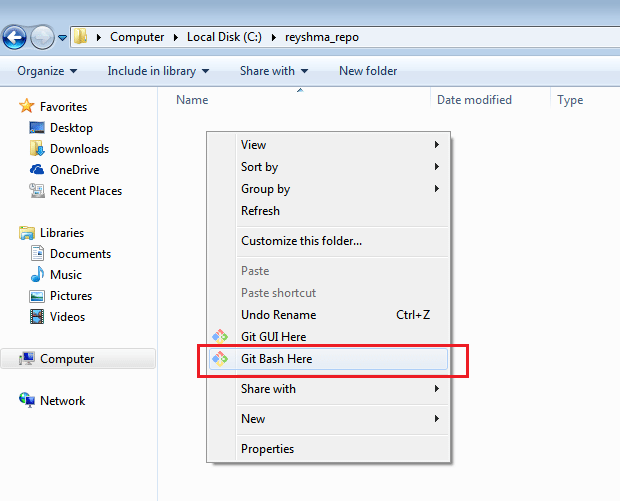
Questo aprirà il terminale Git Bash in cui puoi inserire comandi per eseguire varie operazioni Git.
Ora, il prossimo compito è inizializzare il tuo repository.
Inizializzare
Per fare ciò, utilizziamo il comando git init. Si prega di fare riferimento allo screenshot qui sotto.

git init crea un repository Git vuoto o reinizializza uno esistente. Fondamentalmente crea una directory .git con sottodirectory e file modello. L’esecuzione di un git init in un repository esistente non sovrascriverà le cose che sono già presenti. Raccoglie piuttosto i modelli appena aggiunti.
Ora che il mio repository è inizializzato, fammi creare alcuni file nella directory/repository. Ad esempio, ho creato due file di testo e cioè edureka1.txt e edureka2.txt .
Vediamo se questi file sono nel mio indice o non usano il comando git status . L’indice contiene un’istantanea del contenuto dell’albero/directory di lavoro e questa istantanea viene presa come contenuto per la successiva modifica da apportare nel repository locale.
Stato Git
Il comando git status elenca tutti i file modificati che sono pronti per essere aggiunti al repository locale.
Digitiamo il comando per vedere cosa succede:
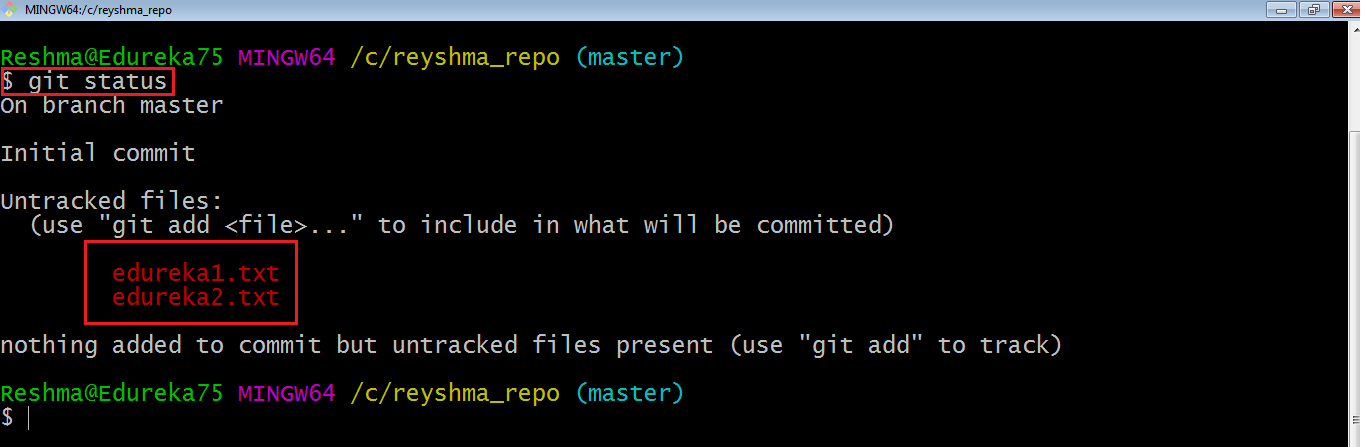
Questo mostra che ho due file che non sono ancora stati aggiunti all’indice. Ciò significa che non posso eseguire il commit delle modifiche con questi file a meno che non li abbia aggiunti esplicitamente nell’indice.
Aggiungere
Questo comando aggiorna l’indice utilizzando il contenuto corrente trovato nell’albero di lavoro e quindi prepara il contenuto nell’area di staging per il prossimo commit.
Pertanto, dopo aver apportato modifiche all’albero di lavoro e prima di eseguire il comando commit , è necessario utilizzare il comando add per aggiungere file nuovi o modificati all’indice. Per questo, usa i comandi seguenti:
git add <directory>
o
git aggiungi <file>
Lascia che ti mostri il git add per te in modo che tu possa capirlo meglio.
Ho creato altri due file edureka3.txt e edureka4.txt . Aggiungiamo i file usando il comando git add -A . Questo comando aggiungerà tutti i file all’indice che si trovano nella directory ma non ancora aggiornati nell’indice.
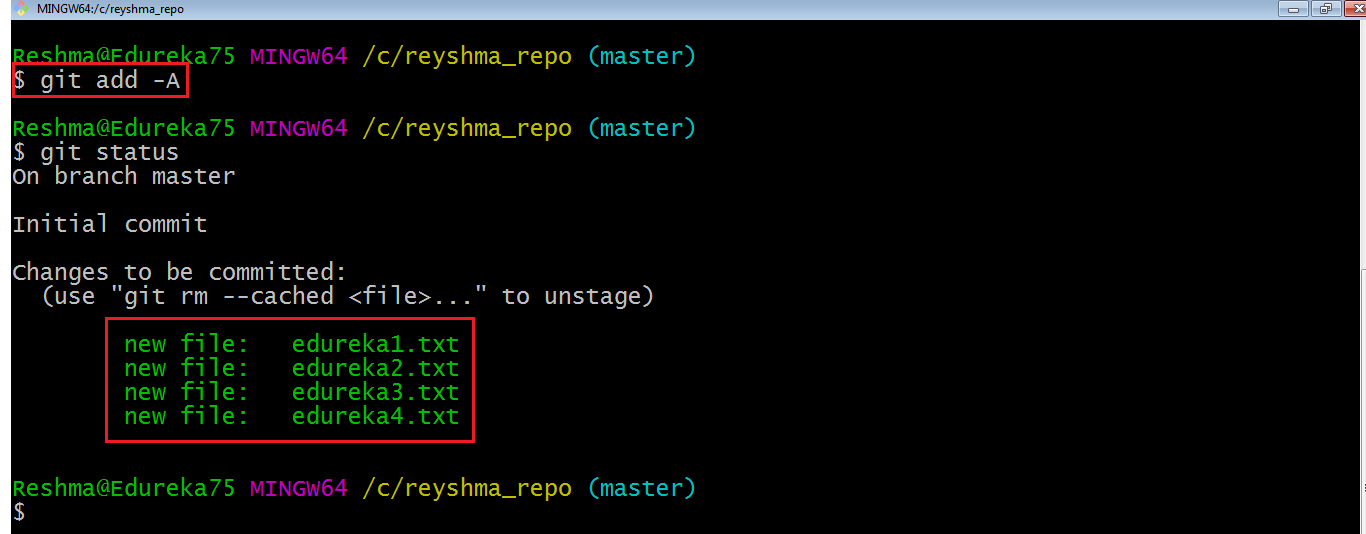
Ora che i nuovi file sono stati aggiunti all’indice, sei pronto per eseguirne il commit.
Commettere
Si riferisce alla registrazione di istantanee del repository in un determinato momento. Gli snapshot vincolati non cambieranno mai a meno che non vengano eseguiti in modo esplicito. Lascia che ti spieghi come funziona il commit con il diagramma seguente:
Qui, C1 è il commit iniziale, cioè lo snapshot della prima modifica da cui viene creato un altro snapshot con le modifiche denominate C2. Nota che il master punta all’ultimo commit.
Ora, quando eseguo di nuovo il commit, viene creata un’altra istantanea C3 e ora il master punta a C3 anziché a C2.
Git mira a mantenere i commit il più leggeri possibile. Quindi, non copia ciecamente l’intera directory ogni volta che esegui il commit; include commit come un insieme di modifiche, o “delta” da una versione del repository all’altra. In parole semplici, copia solo le modifiche apportate nel repository.
Puoi impegnarti usando il comando seguente:
git commit
Questo eseguirà il commit dell’istantanea in stage e avvierà un editor di testo che ti chiederà un messaggio di commit.
Oppure puoi usare:
git commit -m “<messaggio>”
Proviamolo.
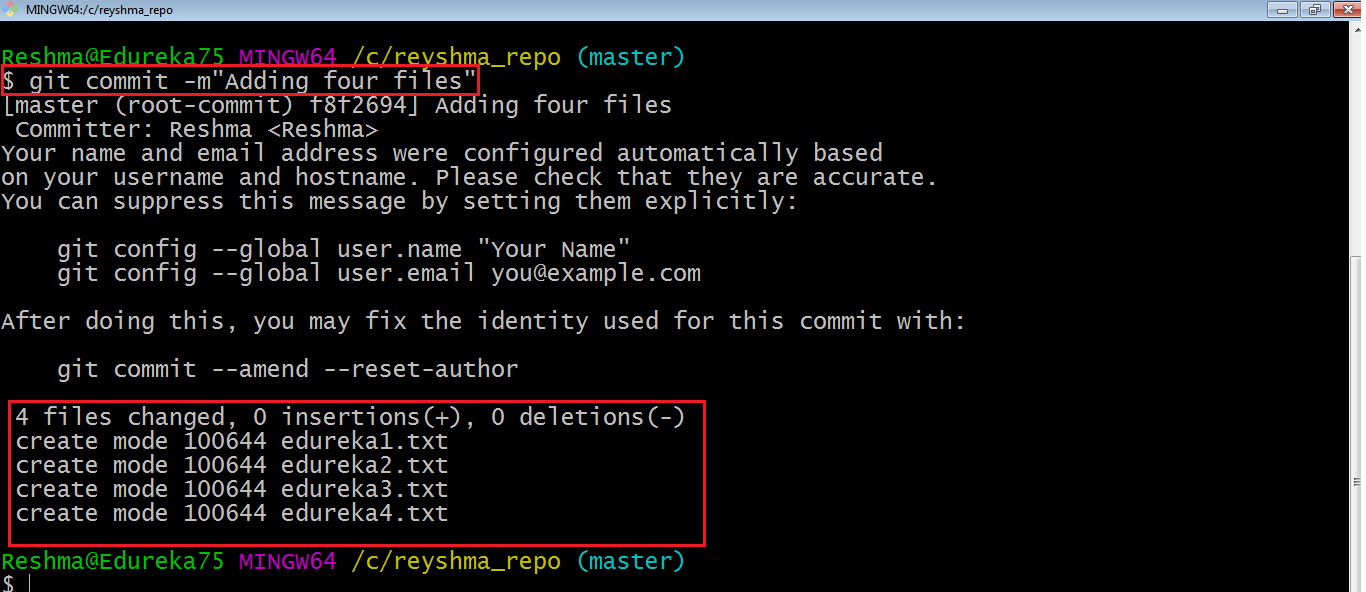
Come puoi vedere sopra, il comando git commit ha eseguito il commit delle modifiche nei quattro file nel repository locale.
Ora, se vuoi eseguire il commit di un’istantanea di tutte le modifiche nella directory di lavoro in una volta, puoi utilizzare il comando seguente:
git commit -a
Ho creato altri due file di testo nella mia directory di lavoro, vale a dire. edureka5.txt e edureka6.txt ma non sono ancora stati aggiunti all’indice.
Sto aggiungendo edureka5.txt usando il comando:
git aggiungi edureka5.txt
Ho aggiunto edureka5.txt all’indice in modo esplicito ma non edureka6.txt e ho apportato modifiche ai file precedenti. Voglio eseguire il commit di tutte le modifiche nella directory in una volta. Fare riferimento allo snapshot qui sotto.
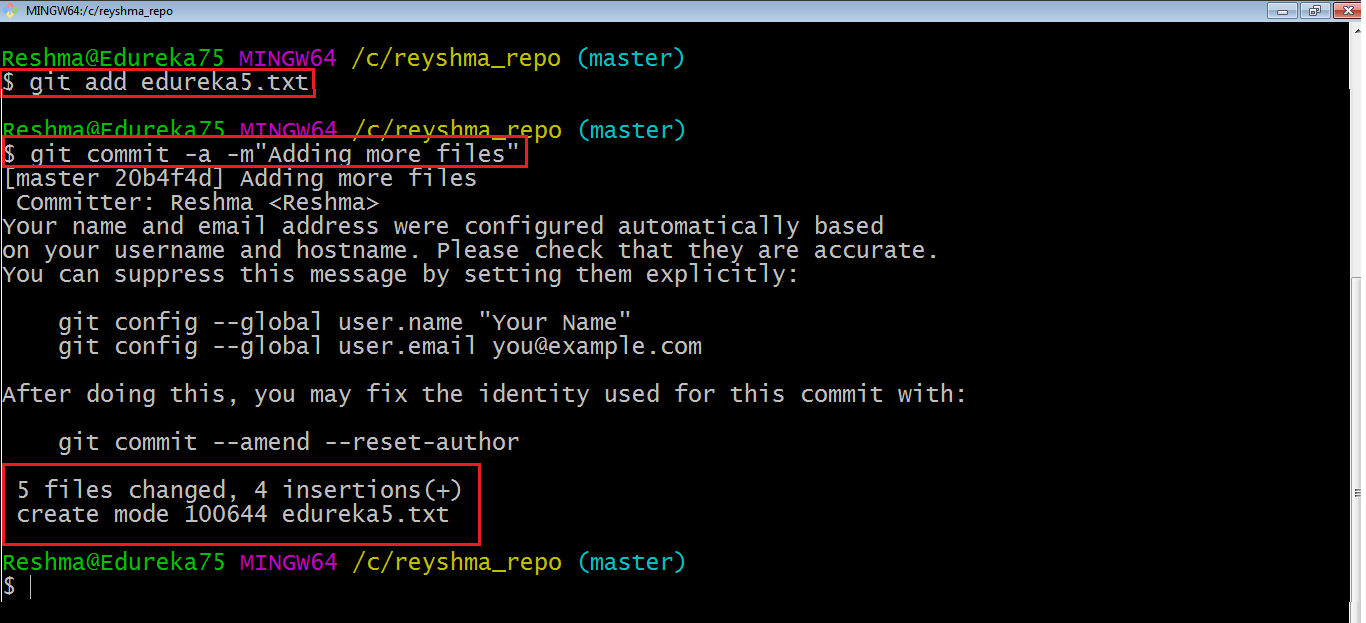
Questo comando eseguirà il commit di un’istantanea di tutte le modifiche nella directory di lavoro, ma include solo le modifiche ai file tracciati, ad esempio i file che sono stati aggiunti con git add ad un certo punto della loro cronologia. Quindi, edureka6.txt non è stato eseguito il commit perché non è stato ancora aggiunto all’indice. Ma le modifiche in tutti i file precedenti presenti nel repository sono state salvate, ovvero edureka1.txt , edureka2.txt , edureka3.txt , edureka4.txt ed edureka5.txt .
Ora ho effettuato i commit desiderati nel mio repository locale.
Nota che prima di modificare le modifiche al repository centrale dovresti sempre eseguire il pull delle modifiche dal repository centrale al tuo repository locale per essere aggiornato con il lavoro di tutti i collaboratori che hanno contribuito al repository centrale. Per questo useremo il comando pull .
Tiro
Il comando git pull recupera le modifiche da un repository remoto a un repository locale. Unisce le modifiche a monte nel tuo repository locale, che è un’attività comune nelle collaborazioni basate su Git.
Ma prima, devi impostare il tuo repository centrale come origine usando il comando:
git remote add origin <link del tuo repository centrale>

Ora che la mia origine è impostata, estraiamo i file dall’origine usando pull. Per questo usa il comando:
git pull origin master
Questo comando copierà tutti i file dal ramo principale del repository remoto al tuo repository locale.

Poiché il mio repository locale è stato già aggiornato con i file del ramo principale, quindi il messaggio è già aggiornato. Fare riferimento alla schermata sopra.
Nota: si può anche provare a estrarre file da un ramo diverso utilizzando il comando seguente:
git pull origin <branch-name>
Il tuo repository Git locale è ora aggiornato con tutte le modifiche recenti. È ora di apportare modifiche al repository centrale utilizzando il comando push .
Spingere
Questo comando trasferisce i commit dal tuo repository locale al tuo repository remoto. È l’opposto dell’operazione di trazione.
Il pull delle importazioni esegue il commit nei repository locali mentre il push delle esportazioni esegue il commit nei repository remoti.
L’uso di git push consiste nel pubblicare le modifiche locali in un repository centrale. Dopo aver accumulato diversi commit locali e sei pronto per condividerli con il resto del team, puoi quindi inviarli al repository centrale utilizzando il comando seguente:
git push <remoto>
Nota : questo telecomando si riferisce al repository remoto che era stato impostato prima di utilizzare il comando pull .
Questo spinge le modifiche dal repository locale al repository remoto insieme a tutti i commit necessari e gli oggetti interni. Questo crea un ramo locale nel repository di destinazione.
Lascia che te lo dimostri.
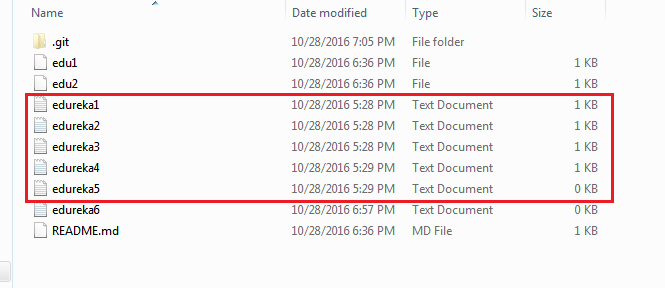
I file di cui sopra sono i file che abbiamo già impegnato in precedenza nella sezione commit e sono tutti ” pronti per il push “. Userò il comando git push origin master per riflettere questi file nel ramo master del mio repository centrale.
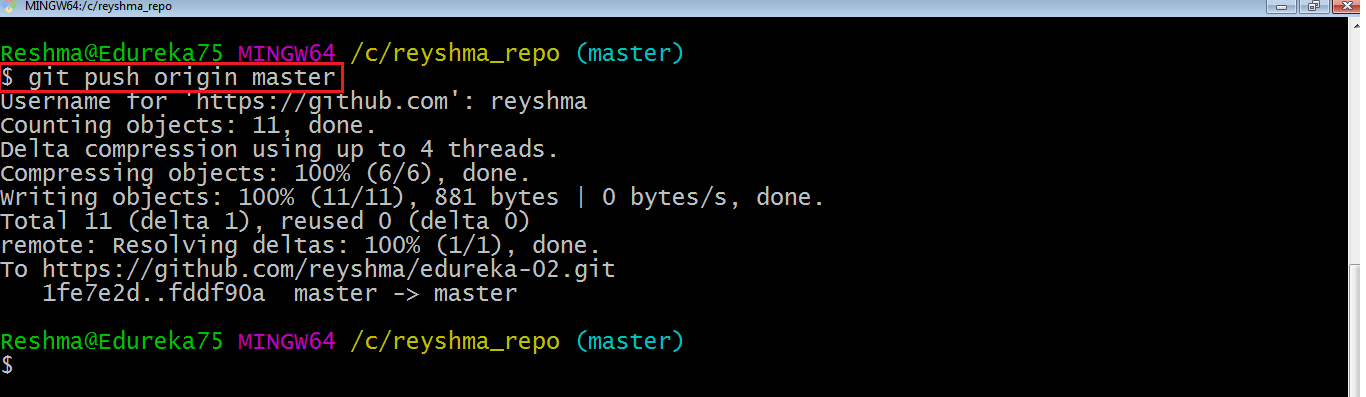
Verifichiamo ora se le modifiche sono avvenute nel mio repository centrale.
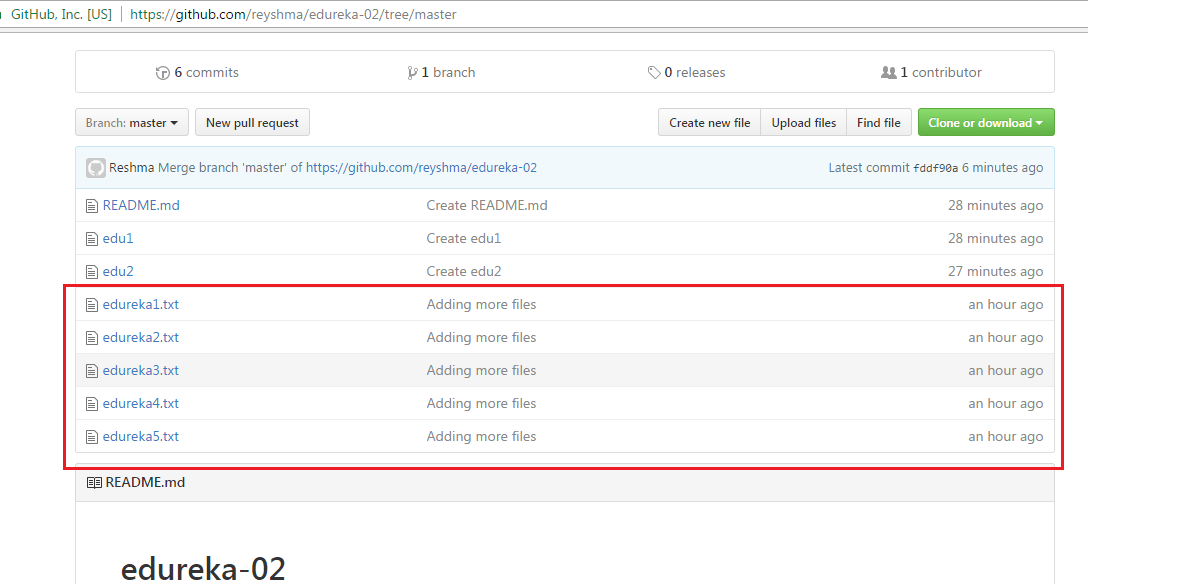
Sì, l’ha fatto. 🙂
Per impedire la sovrascrittura, Git non consente il push quando risulta in un’unione non rapida nel repository di destinazione.
Nota : un’unione non rapida in avanti significa un’unione a monte, ovvero la fusione con rami predecessori o padre da un ramo figlio.
Per abilitare tale unione, utilizzare il comando seguente:
git push <remoto> –force
Il comando precedente forza l’operazione di push anche se risulta in un’unione in avanti non rapida.
A questo punto di questo tutorial su Git, spero che tu abbia compreso i comandi di base di Git. Ora, facciamo un ulteriore passo avanti per imparare a ramificare e unire in Git.
Ramificazione
I rami in Git non sono altro che puntatori a un commit specifico. Git generalmente preferisce mantenere i suoi rami il più leggeri possibile.
Ci sono fondamentalmente due tipi di rami vale a dire. filiali locali e filiali di monitoraggio remoto .
Un ramo locale è solo un altro percorso del tuo albero di lavoro. D’altra parte, le filiali di tracciamento remoto hanno scopi speciali. Alcuni di loro sono:
- Collegano il tuo lavoro dal repository locale al lavoro sul repository centrale.
- Rilevano automaticamente da quali rami remoti ottenere le modifiche, quando usi git pull .
Puoi controllare qual è il tuo ramo attuale usando il comando:
ramo git
L’unico mantra che dovresti sempre cantare mentre ti ramifichi è “ramifica presto e ramifica spesso”
Per creare un nuovo ramo utilizziamo il seguente comando:
git branch <nome-ramo>
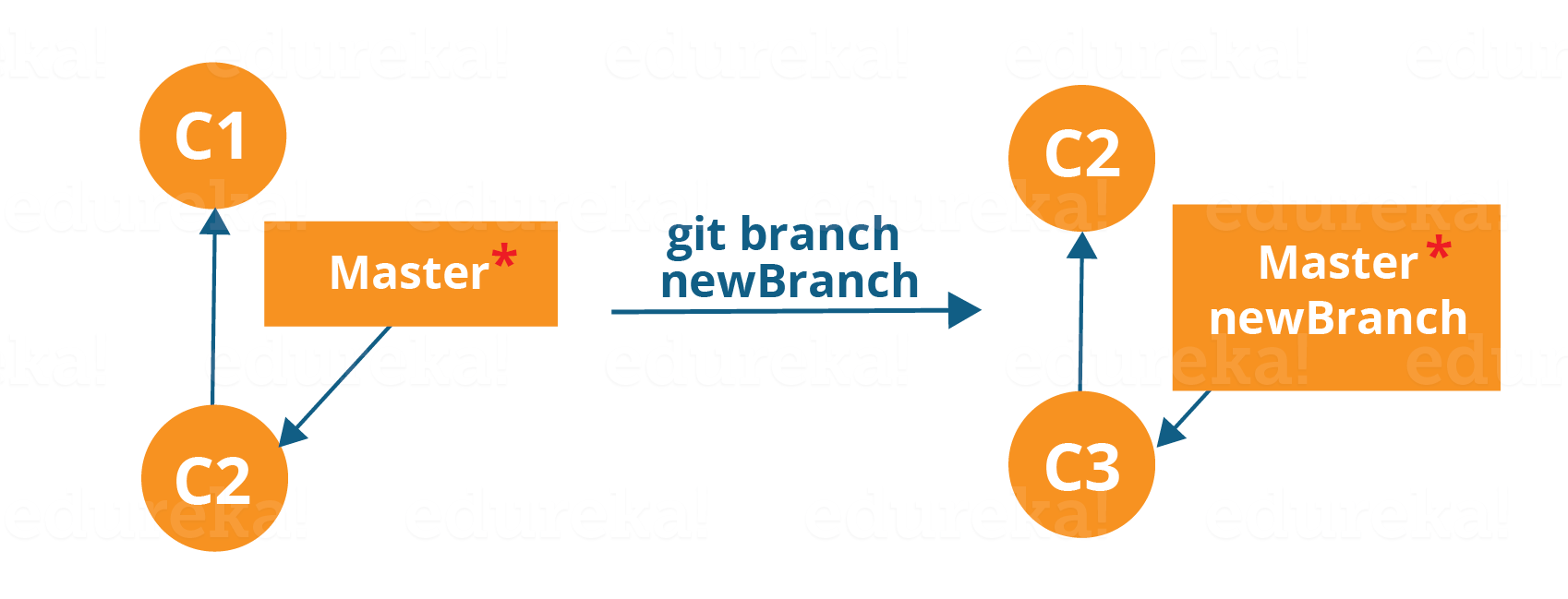
Il diagramma sopra mostra il flusso di lavoro quando viene creato un nuovo ramo. Quando creiamo un nuovo ramo, ha origine dal ramo principale stesso.
Dal momento che non c’è spazio di archiviazione/memoria durante la creazione di molti rami, è più facile dividere logicamente il tuo lavoro piuttosto che avere rami grandi e grossi.
Ora, vediamo come eseguire il commit usando i rami.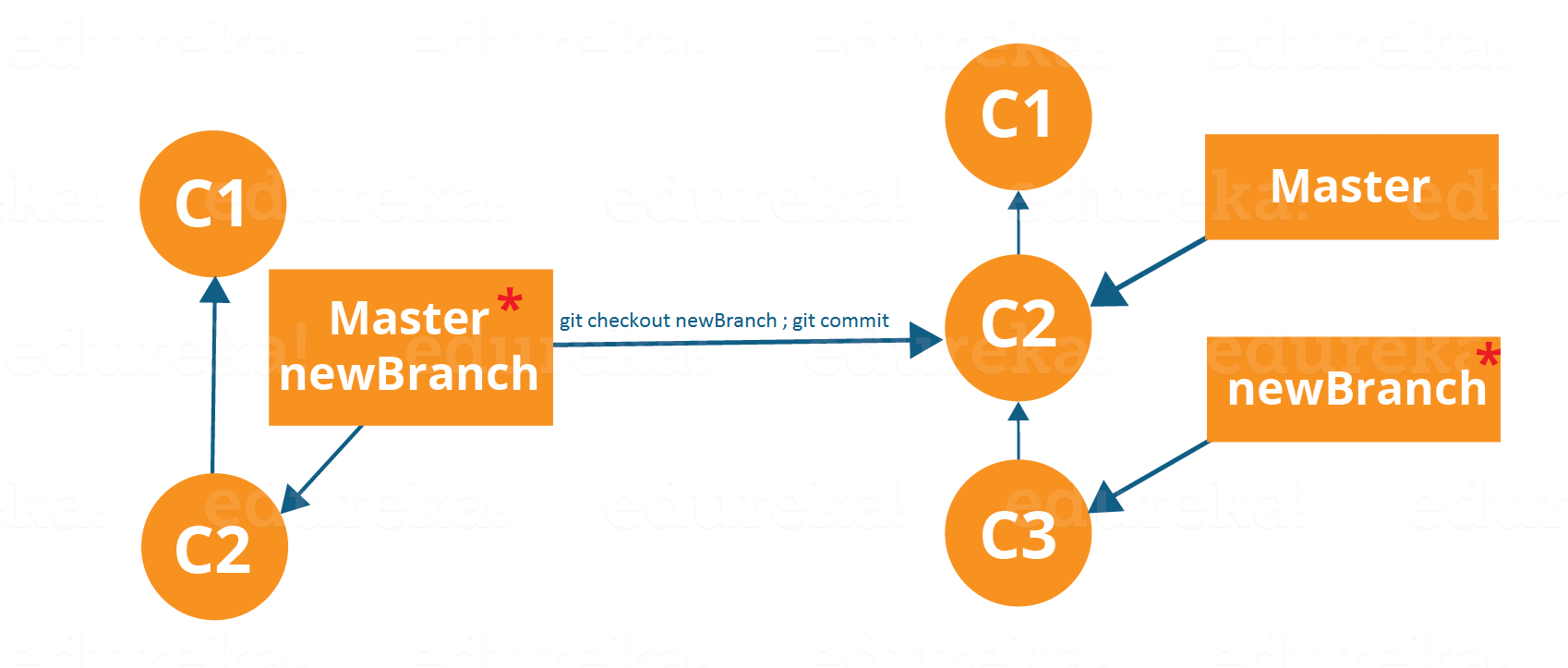
La ramificazione include il lavoro di un commit particolare insieme a tutti i commit principali. Come puoi vedere nel diagramma sopra, il newBranch si è staccato dal master e quindi creerà un percorso diverso.
Usa il comando seguente:
git checkout <branch_name> e poi
git commit
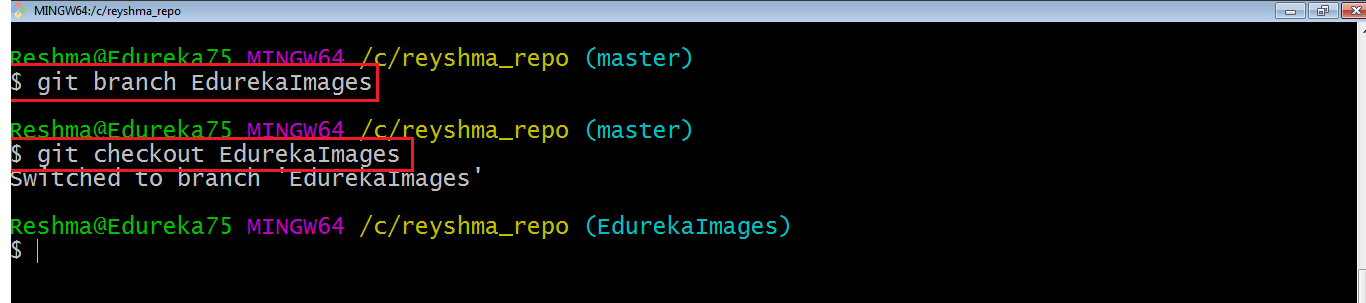
Qui ho creato un nuovo ramo chiamato “EdurekaImages” e sono passato al nuovo ramo usando il comando git checkout .
Una scorciatoia per i comandi precedenti è:
git checkout -b[ nome_ramo]
Questo comando creerà un nuovo ramo e verificherà il nuovo ramo allo stesso tempo.
Ora mentre siamo nel ramo EdurekaImages, aggiungi e salva il file di testo edureka6.txt usando i seguenti comandi:
git aggiungi edureka6.txt
git commit -m”aggiungendo edureka6.txt”
Fusione
La fusione è il modo per combinare insieme il lavoro di diversi rami. Questo ci consentirà di diramare, sviluppare una nuova funzionalità e quindi ricombinarla.

Il diagramma sopra ci mostra due diversi rami-> newBranch e master. Ora, quando uniamo il lavoro di newBranch in master, viene creato un nuovo commit che contiene tutto il lavoro di master e newBranch.
Ora uniamo i due rami con il comando seguente:
git merge <nome_ramo>
È importante sapere che il nome del ramo nel comando precedente dovrebbe essere il ramo che si desidera unire al ramo che si sta attualmente ritirando. Quindi, assicurati di essere estratto nel ramo di destinazione.
Ora uniamo tutto il lavoro del ramo EdurekaImages nel ramo principale. Per questo controllerò prima il ramo master con il comando git checkout master e unirò EdurekaImages con il comando git merge EdurekaImages
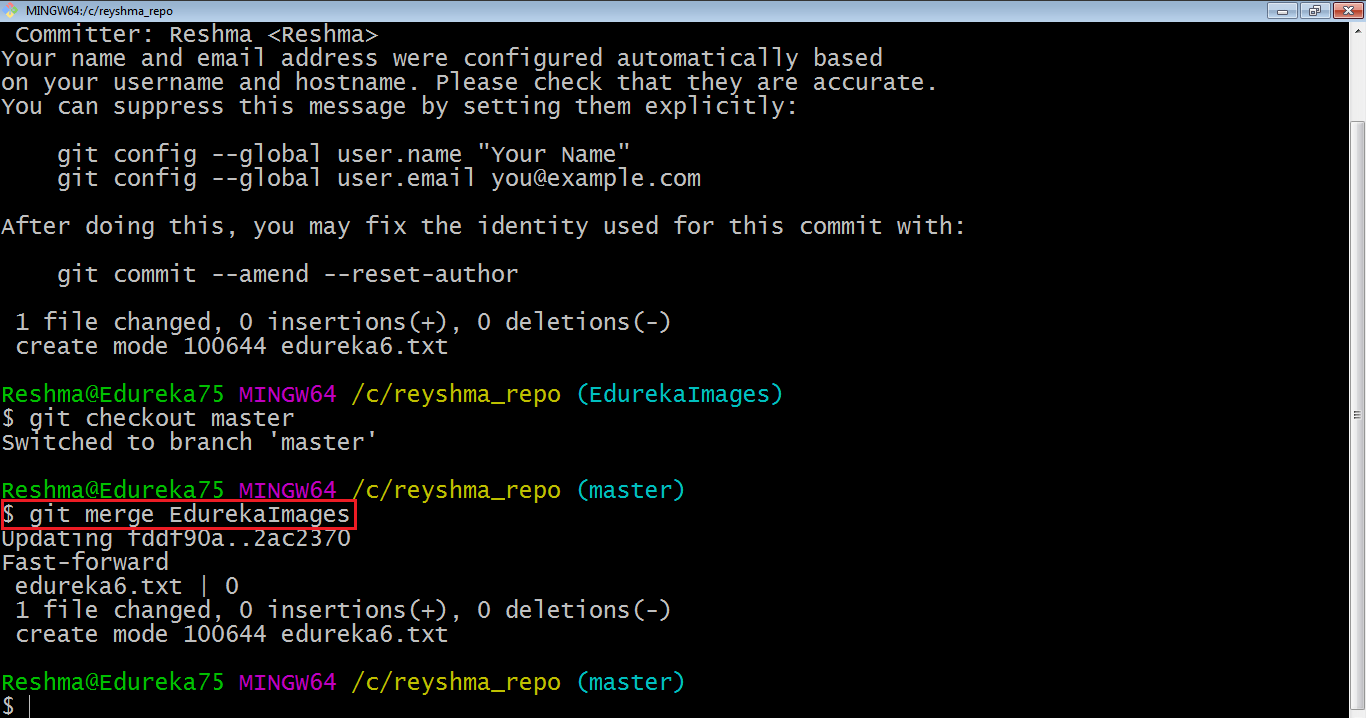
Come puoi vedere sopra, tutti i dati del nome del ramo vengono uniti al ramo principale. Ora il file di testo edureka6.txt è stato aggiunto al ramo principale.
L’unione in Git crea un commit speciale che ha due genitori univoci.
Ribasatura
Questo è anche un modo per combinare il lavoro tra diversi rami. Il rebasing prende una serie di commit, li copia e li archivia al di fuori del tuo repository.
Il vantaggio del rebasing è che può essere utilizzato per creare sequenze lineari di commit. Il registro dei commit o la cronologia del repository rimangono puliti se viene eseguita la ribasatura.
Vediamo come succede.
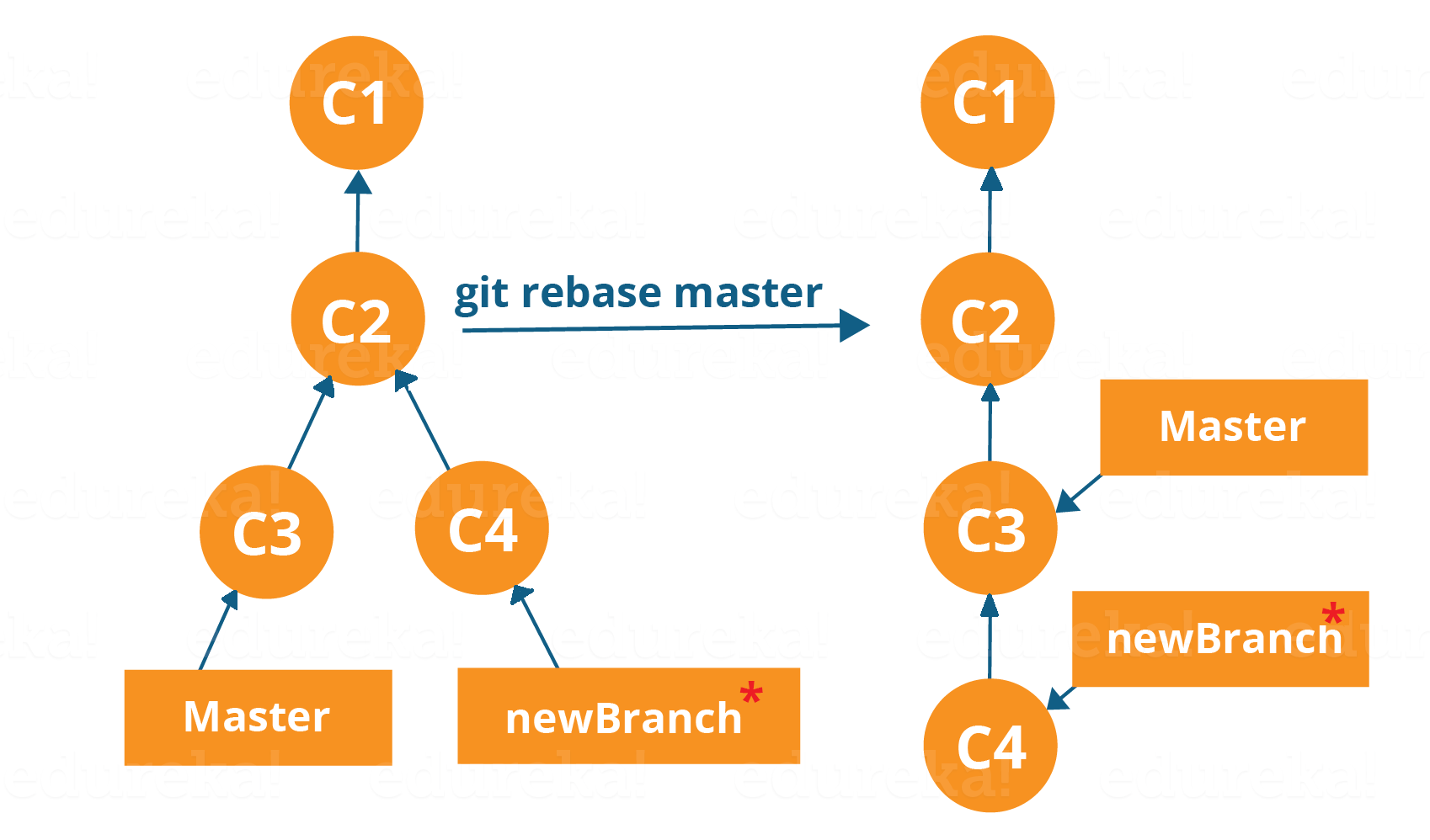
Ora, il nostro lavoro da newBranch è posizionato subito dopo il master e abbiamo una bella sequenza lineare di commit.
Nota : il ribasamento impedisce anche le unioni a monte, il che significa che non puoi posizionare master subito dopo newBranch.
Ora, per rebase master, digita il comando seguente in Git Bash:
git rebase master

Questo comando sposterà tutto il nostro lavoro dal ramo corrente al master. Sembrano sviluppati in sequenza, ma sono sviluppati parallelamente.
Git Tutorial – Suggerimenti e trucchi
Ora che hai eseguito tutte le operazioni in questo tutorial su Git, ecco alcuni suggerimenti e trucchi che dovresti conoscere. 🙂
- Archivia il tuo repository
Usa il seguente comando-
git archivio master –format=zip –output= ../nome-del-file.zip
Memorizza tutti i file e i dati in un file zip anziché nella directory .git .
Si noti che questo crea solo un singolo snapshot omettendo completamente il controllo della versione. Questo è utile quando vuoi inviare i file a un client per la revisione che non ha Git installato nel proprio computer.
- Raggruppa il tuo repository
Trasforma un repository in un unico file.
Usa il seguente comando-
git bundle create ../repo.bundler master
Questo spinge il ramo principale a un ramo remoto, contenuto solo in un file anziché in un repository.
Un modo alternativo per farlo è:
CD..
git clone repo.bundle repo-copy -b master
copia repo del cd
registro git
cd.. /mio-git-repo
- Riponi le modifiche non vincolate
Quando vogliamo annullare temporaneamente l’aggiunta di una funzione o di qualsiasi tipo di dati aggiunti, possiamo “riporli” temporaneamente.
Usa il comando seguente:
stato git
git scorta
stato git
E quando vuoi riapplicare le modifiche che hai “riposto”, usa il comando seguente:
git stash si applica
Spero che questo tutorial su Git Bash ti sia piaciuto e che tu abbia imparato i comandi e le operazioni in Git. Fammi sapere se vuoi saperne di più su Git nella sezione commenti qui sotto 🙂