
Le reti neurali profonde sono diventate famose per la loro capacità di elaborare le informazioni visive. E negli ultimi anni sono diventati un componente chiave di molte applicazioni di visione artificiale.
Tra i problemi chiave che le reti neurali possono risolvere c’è il rilevamento e la localizzazione di oggetti nelle immagini. Il rilevamento degli oggetti viene utilizzato in molti domini diversi, tra cui la guida autonoma, la videosorveglianza e l’assistenza sanitaria.
In questo post esaminerò brevemente le architetture di deep learning che aiutano i computer a rilevare gli oggetti.
Reti neurali convoluzionali
Uno dei componenti chiave della maggior parte delle applicazioni di visione artificiale basate sull’apprendimento profondo è la rete neurale convoluzionale (CNN). Inventate negli anni ’80 dal pioniere del deep learning Yann LeCun , le CNN sono un tipo di rete neurale efficiente nel catturare modelli in spazi multidimensionali. Ciò rende le CNN particolarmente adatte per le immagini, sebbene vengano utilizzate anche per elaborare altri tipi di dati. (Per concentrarci sui dati visivi, in questo articolo considereremo le nostre reti neurali convoluzionali bidimensionali.)
Ogni rete neurale convoluzionale è composta da uno o più livelli convoluzionali , un componente software che estrae valori significativi dall’immagine di input. E ogni livello di convoluzione è composto da diversi filtri, matrici quadrate che scorrono sull’immagine e registrano la somma ponderata dei valori dei pixel in posizioni diverse. Ogni filtro ha valori diversi ed estrae caratteristiche diverse dall’immagine di input. L’output di un livello di convoluzione è un insieme di “mappe di funzionalità”.
Quando impilati uno sopra l’altro, i livelli convoluzionali possono rilevare una gerarchia di modelli visivi. Ad esempio, i livelli inferiori produrranno mappe di caratteristiche per bordi verticali e orizzontali, angoli e altri modelli semplici. I livelli successivi possono rilevare modelli più complessi come griglie e cerchi. Man mano che ti addentri nella rete, i livelli rileveranno oggetti complicati come automobili, case, alberi e persone.

La maggior parte delle reti neurali convoluzionali utilizza i livelli di pooling per ridurre gradualmente le dimensioni delle mappe delle caratteristiche e mantenere le parti più importanti. Max-pooling, che è attualmente il tipo principale di livello di pool utilizzato nelle CNN, mantiene il valore massimo in una patch di pixel. Ad esempio, se si utilizza un livello di pooling con dimensione 2, verranno prelevate patch 2×2 pixel dalle mappe di funzionalità prodotte dal livello precedente e manterrà il valore più alto. Questa operazione dimezza la dimensione delle mappe e mantiene le caratteristiche più rilevanti. I livelli di pooling consentono alle CNN di generalizzare le proprie capacità ed essere meno sensibili allo spostamento degli oggetti attraverso le immagini.
Infine, l’output dei livelli di convoluzione viene appiattito in una matrice unidimensionale che è la rappresentazione numerica delle caratteristiche contenute nell’immagine. Quella matrice viene quindi inserita in una serie di strati “completamente connessi” di neuroni artificiali che mappano le caratteristiche in base al tipo di output atteso dalla rete.
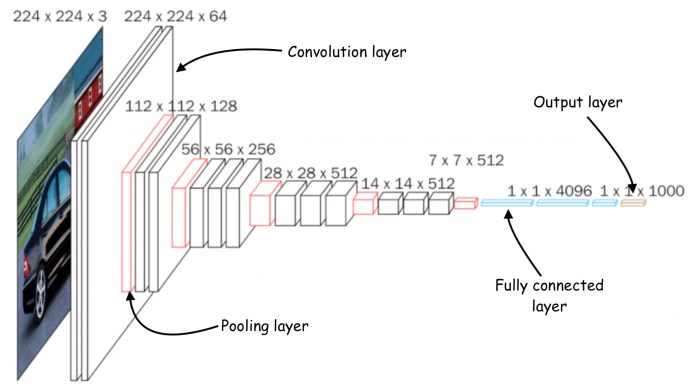
Il compito più basilare per le reti neurali convoluzionali è la classificazione delle immagini, in cui la rete prende un’immagine come input e restituisce un elenco di valori che rappresentano la probabilità che l’immagine appartenga a una delle diverse classi.
Ad esempio, supponiamo di voler addestrare una rete neurale per rilevare tutte le 1.000 classi di oggetti contenute nel popolare set di dati open source ImageNet . In tal caso, il tuo livello di output avrà 1.000 output numerici, ognuno dei quali contiene la probabilità che l’immagine appartenga a una di quelle classi.
Puoi sempre creare e testare la tua rete neurale convoluzionale da zero. Ma la maggior parte dei ricercatori e sviluppatori di machine learning utilizza una delle numerose reti neurali convoluzionali collaudate come AlexNet, VGG16 e ResNet-50.
Set di dati di rilevamento di oggetti
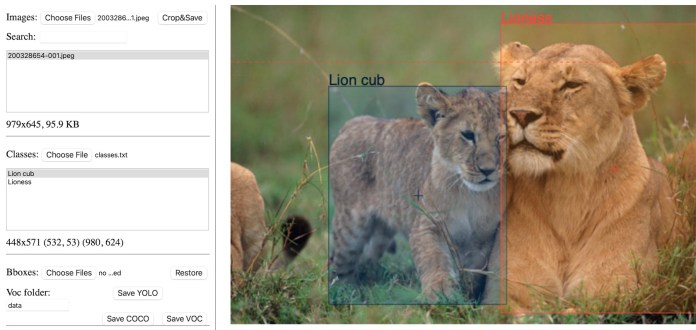
Mentre una rete di classificazione delle immagini può dire se un’immagine contiene o meno un determinato oggetto, non dirà dove si trova l’oggetto nell’immagine. Le reti di rilevamento degli oggetti forniscono sia la classe di oggetti contenuti in un’immagine che un riquadro di delimitazione che fornisce le coordinate di quell’oggetto.
Le reti di rilevamento degli oggetti assomigliano molto alle reti di classificazione delle immagini e utilizzano i livelli di convoluzione per rilevare le caratteristiche visive. In effetti, la maggior parte delle reti di rilevamento di oggetti utilizza una CNN di classificazione delle immagini e la riutilizza per il rilevamento di oggetti.
Il rilevamento degli oggetti è un problema di apprendimento automatico supervisionato , il che significa che devi addestrare i tuoi modelli su esempi etichettati. Ogni immagine nel set di dati di training deve essere accompagnata da un file che includa i limiti e le classi degli oggetti che contiene. Esistono diversi strumenti open source che creano annotazioni di rilevamento degli oggetti.
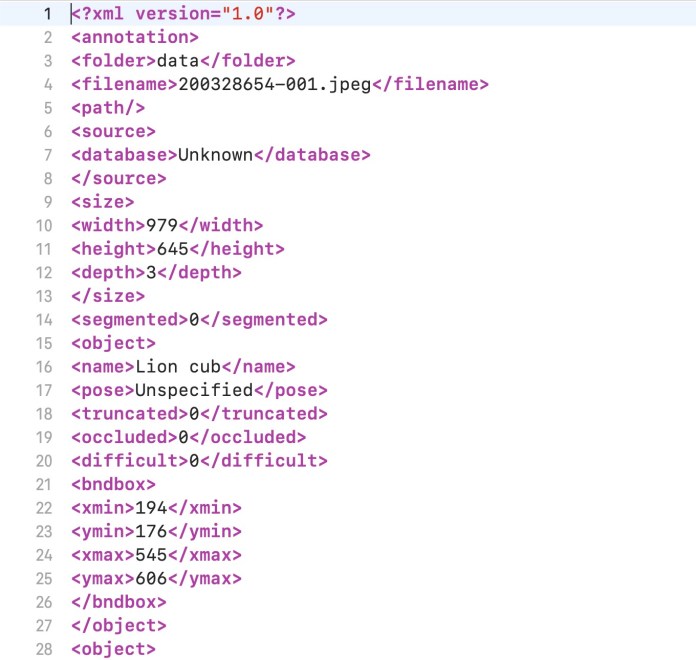
La rete di rilevamento degli oggetti viene addestrata sui dati annotati fino a quando non riesce a trovare regioni nelle immagini che corrispondono a ciascun tipo di oggetto.
Ora diamo un’occhiata ad alcune architetture di reti neurali per il rilevamento di oggetti.
Il modello di deep learning di R-CNN
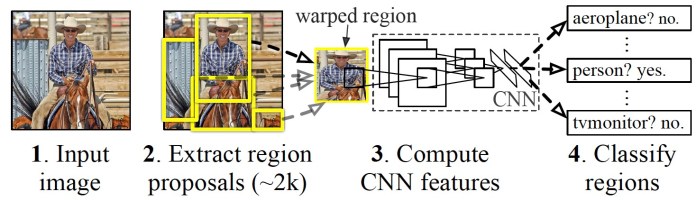
La rete neurale convoluzionale regionale (R-CNN) è stata proposta dai ricercatori di intelligenza artificiale presso l’Università della California, Berkley, nel 2014. La R-CNN è composta da tre componenti chiave.
Innanzitutto, un selettore di regione utilizza un algoritmo di “ricerca selettiva”, che trova regioni di pixel nell’immagine che potrebbero rappresentare oggetti, chiamate anche “regioni di interesse” (RoI). Il selettore della regione genera circa 2.000 regioni di interesse per ogni immagine.
Successivamente, le RoI vengono deformate in una dimensione predefinita e passate a una rete neurale convoluzionale. La CNN elabora ogni regione separatamente estraendone le caratteristiche attraverso una serie di operazioni di convoluzione. La CNN utilizza livelli completamente connessi per codificare le mappe delle caratteristiche in un vettore unidimensionale di valori numerici.
Infine, un modello di apprendimento automatico classificatore mappa le funzionalità codificate ottenute dalla CNN alle classi di output. Il classificatore ha una classe di output separata per “sfondo”, che corrisponde a tutto ciò che non è un oggetto.

Il documento originale della R-CNN suggerisce la rete neurale convoluzionale AlexNet per l’estrazione delle caratteristiche e una macchina vettoriale di supporto (SVM) per la classificazione. Ma negli anni successivi alla pubblicazione del documento, i ricercatori hanno utilizzato architetture di rete e modelli di classificazione più recenti per migliorare le prestazioni di R-CNN.
R-CNN soffre di alcuni problemi. Innanzitutto, il modello deve generare e ritagliare 2.000 regioni separate per ogni immagine, operazione che può richiedere parecchio tempo. In secondo luogo, il modello deve calcolare separatamente le caratteristiche per ciascuna delle 2.000 regioni. Ciò comporta molti calcoli e rallenta il processo, rendendo R-CNN inadatto al rilevamento di oggetti in tempo reale. Infine, il modello è composto da tre componenti separati, il che rende difficile l’integrazione dei calcoli e il miglioramento della velocità.
R-CNN veloce
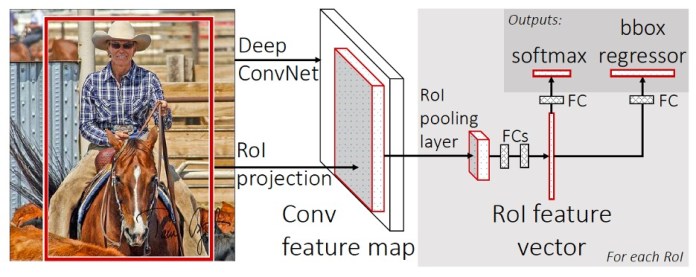
Nel 2015, l’autore principale del documento R-CNN ha proposto una nuova architettura chiamata Fast R-CNN , che ha risolto alcuni dei problemi del suo predecessore. Fast R-CNN porta l’estrazione delle funzionalità e la selezione della regione in un unico modello di machine learning.
Fast R-CNN riceve un’immagine e un insieme di RoI e restituisce un elenco di riquadri di delimitazione e classi degli oggetti rilevati nell’immagine.
Una delle innovazioni chiave di Fast R-CNN è stata il “RoI pooling layer”, un’operazione che utilizza le mappe delle caratteristiche della CNN e le regioni di interesse per un’immagine e fornisce le caratteristiche corrispondenti per ciascuna regione. Ciò ha consentito a Fast R-CNN di estrarre le caratteristiche per tutte le regioni di interesse nell’immagine in un unico passaggio rispetto a R-CNN, che ha elaborato ciascuna regione separatamente. Ciò ha comportato un aumento significativo della velocità.
Tuttavia, un problema è rimasto irrisolto. Fast R-CNN richiedeva ancora che le regioni dell’immagine venissero estratte e fornite come input al modello. Fast R-CNN non era ancora pronto per il rilevamento di oggetti in tempo reale.
R-CNN più veloce
[architettura r-cnn più veloce]
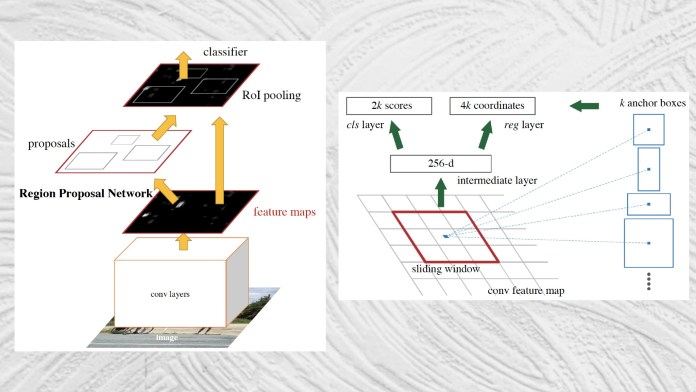
Faster R-CNN , introdotto nel 2016, risolve il pezzo finale del puzzle di rilevamento degli oggetti integrando il meccanismo di estrazione della regione nella rete di rilevamento degli oggetti.
R-CNN più veloce prende un’immagine come input e restituisce un elenco di classi di oggetti e le loro caselle di delimitazione corrispondenti.
L’architettura di Faster R-CNN è in gran parte simile a quella di Fast R-CNN. La sua principale innovazione è la “regione proposta di rete” (RPN), un componente che prende le mappe delle caratteristiche prodotte da una rete neurale convoluzionale e propone un insieme di scatole di delimitazione in cui potrebbero essere posizionati gli oggetti. Le regioni proposte vengono quindi passate al livello di pooling RoI. Il resto del processo è simile a Fast R-CNN.
Integrando il rilevamento della regione nell’architettura della rete neurale principale, Faster R-CNN raggiunge una velocità di rilevamento degli oggetti quasi in tempo reale.
YOLO
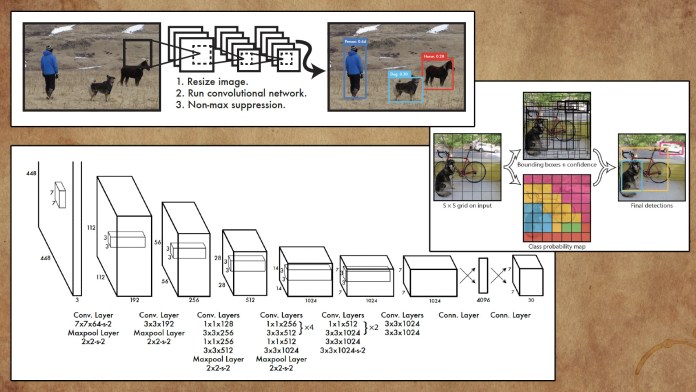
Nel 2016, i ricercatori della Washington University, dell’Allen Institute for AI e di Facebook AI Research hanno proposto “You Only Look Once” ( YOLO ), una famiglia di reti neurali che ha migliorato la velocità e l’accuratezza del rilevamento degli oggetti con il deep learning.
Il principale miglioramento di YOLO è l’integrazione dell’intero processo di rilevamento e classificazione degli oggetti in un’unica rete. Invece di estrarre funzionalità e regioni separatamente, YOLO esegue tutto in un unico passaggio attraverso un’unica rete, da cui il nome “You Only Look Once”.
YOLO può eseguire il rilevamento di oggetti a frame rate di streaming video ed è un’applicazione adatta che richiede l’inferenza in tempo reale.
Negli ultimi anni, il rilevamento di oggetti di deep learning ha fatto molta strada, evolvendosi da un patchwork di diversi componenti a una singola rete neurale che funziona in modo efficiente. Oggi molte applicazioni utilizzano le reti di rilevamento degli oggetti come uno dei loro componenti principali. È nel telefono, nel computer, nell’auto, nella fotocamera e altro ancora. Sarà interessante (e forse inquietante) vedere cosa si può ottenere con reti neurali sempre più avanzate.